
Overview
With our AKS Kubernetes cluster in place we’re now ready to start using it, we’ll do this by creating some Kubernetes Pods and Deployments via configurations
📕 Kubernetes Glossary. A Pod is a group of one or more containers running in the cluster. For this lab we will deploy single pod containers, although not technically correct for now you can think of a pod being equivalent to a container.
A Deployment is a logical object representing a set of replicated pods, managed by a ReplicaSet. The Deployment will manage things such as rolling updates, scaling etc. In general you make changes to Deployments and not directly to Pods
We have three microservices we need to deploy, and due to dependencies between them we’ll start with the MongoDB database then the Data API and then finally move onto the Frontend
We’ll apply configurations to Kubernetes using kubectl and YAML configuration files. These YAML files will describe the objects we want to create, modify and delete in the cluster.
We’ll create a new project directory to work out of for this lab
mkdir kube-lab
cd kube-lab
Cloud Shell Editor
If using the Azure Cloud Shell, it’s strongly recommended to use the built-in online editor which is invoked with the command
code .
Note the dot after the command, it’s recommended you invoke the editor this way as it will then show a file explorer view for the current directory.
When creating a new file use the touch command to create an empty file, e.g. touch foo.yaml, then in the editor click refresh icon at the top of the files view in order to see the file and open it for editing. There are other ways to use the Cloud Shell Editor, but this workflow is recommended
Deploy MongoDB
Create a new file called mongo.deploy.yaml (run touch mongo.deploy.yaml and refresh the files view in the editor) and paste the following contents in it, and save:
kind: Deployment
apiVersion: apps/v1
metadata:
name: mongodb
spec:
replicas: 1
selector:
matchLabels:
app: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongodb-pod
image: mongo:3.4-jessie
ports:
- containerPort: 27017
💬 Note. YAML is sensitive to indentation and white space, so be extra mindful of this when copy & pasting
There’s a lot going on here but we’ll cover of some of the concepts:
- We’re declaring a Deployment named mongodb
- This deployment will create a replicated set of pods (using ReplicaSet), however for this MongoDB deployment we’ll run just 1 pod
- The Pod will run a container from the
mongo:3.4-jessieimage, which will be pulled from Dockerhub. This is the standard official MongoDB image, it is not specific to our Smilr application - The container will expose TCP port 27017 out to the Pod and the cluster
- We apply label metadata
app=mongodbwhich we’ll use to help locate the pods later. This labelling is completely up to us, it’s just arbitrary key value pairs
To apply this configuration to the cluster we run:
kubectl apply -f mongo.deploy.yaml
If successful you will see deployment "mongodb" created. You can check the status of your cluster with this command (or you can use the dashboard)
kubectl get all
You should see a deployment called mongo (prefixed deploy/) a replica set (prefixed rs/) and a pod (prefixed po/), the pod and replica set will have auto generated names appended.
Each pod in Kubernetes gets its own IP address within the cluster. If you are interested, it is worth spending 5 minutes reading some of the concepts
📘 Kubernetes network concepts
To get the pod’s IP address run the describe pod command with a filter set to our app=mongodb label
kubectl describe pod -l app=mongodb
You can find the IP in the output (it will be a 10.244.x.x address), make a note of it, we’ll use it in the next step
💬 Note. The kubectl command supports a number of different output formats, including JSON, YAML and a syntax called JSONPath which allows you to filter and query the output. So in order to just get the IP address we could also have run: kubectl get pod -l app=mongodb -o=jsonpath='{.items[0].status.podIP}{"\n"}'
Deploy Data API
Create a new file called data-api.deploy.yaml (run touch data-api.deploy.yaml and refresh the files view in the editor) and paste the contents below in it. You will need to replace {acr_name} and {mongo_ip} with their real values.
If you skipped Part 2 you are not using ACR, then you can omit the registry and just use smilr/data-api as the image and remove the imagePullSecrets: section
kind: Deployment
apiVersion: apps/v1
metadata:
name: data-api
spec:
replicas: 1
selector:
matchLabels:
app: data-api
template:
metadata:
labels:
app: data-api
spec:
containers:
- name: data-api-pod
image: {acr_name}.azurecr.io/smilr/data-api
ports:
- containerPort: 4000
env:
- name: MONGO_CONNSTR
value: mongodb://{mongo_ip}
imagePullSecrets:
- name: acr-auth
As before, to apply this configuration to the cluster we run:
kubectl apply -f data-api.deploy.yaml
You can check the status with either the dashboard, or a couple of commands, a basic check is running kubectl get pods and check the pod(s) are in Running status. However this status can sometimes be misleading.
A better picture can be found using kubectl logs to view the stdout & stderr inside the running containers. This view the logs of all our data-api pods (all one of them)
kubectl logs -l app=data-api
Check the output for log messages confirming the app has connected to MongoDB OK and has started listening on port 4000
Access Smilr Data API
Now how do we access the Smilr Data API? One quick way is to use port forwarding to create a ‘tunnel’ into the cluster using kubectl port-forward.
First get the name of of the Data API pod with:
kubectl get pods
Then start the port forwarding tunnel from localhost port 8080 to the container port 4000. You should run this in a new Cloud Shell tab, so open that first:
kubectl port-forward {data_api_pod_name} 8080:4000
Now switch back to the main Cloud Shell tab and access the Data API by running
curl localhost:8080/api/info | jq
This should return some system & status information from the Smilr API as JSON. You can now use Ctrl+C to stop the kubectl port-forward command and close the tunnel.
End of Module 3
What we have have at this stage in Kubernetes can be represented as follows
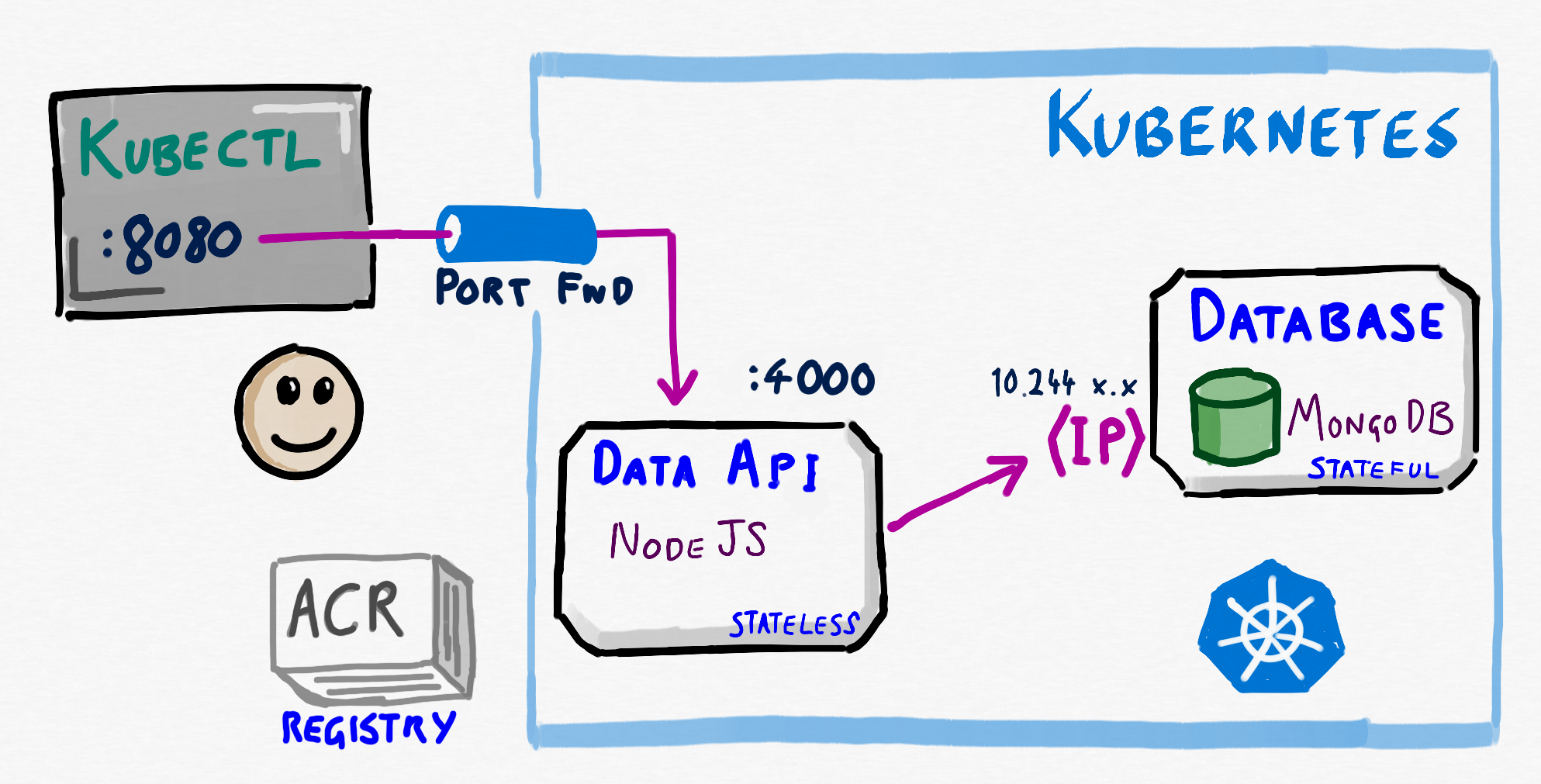
Now this is not a recommended configuration for a lot of reasons, and in the next module we will examine why, and start to rectify it
🡸 Module 2: Azure Container Registry (ACR) 🡺 Module 4: Services & Networking
Leave a comment