
This guide will run through the custom integration that was created for Azure Citadel to use the Azure Search service to index the site and provide search results to users. Although the solution was specific to this site and Jekyll, the working principals and approach could be reused for integrating any static website with Azure Search
Azure Search is a search-as-a-service cloud solution that gives developers APIs and tools for adding a rich search experience over heterogenous content in a range of applications
Using Azure Search with a static site like Jekyll presented several challenges
- Generating site content (Markdown and HTML pages) in generalised a data format Azure Search can consume and index
- Getting said data into Azure Search
- Allowing users to query the search from the site, i.e. creating the frontend
Solution Components
The solution consists of four main elements:
- Jekyll page (Liquid template) that outputs site as JSON
- GitHub action for pushing data into Azure Search index
- Azure Search service
- Search page ‘client’ written in jQuery & HTML5
- App Insights for analytics and gathering telemetry
End to End Data Flow
The data flow and interaction between the components is as follows
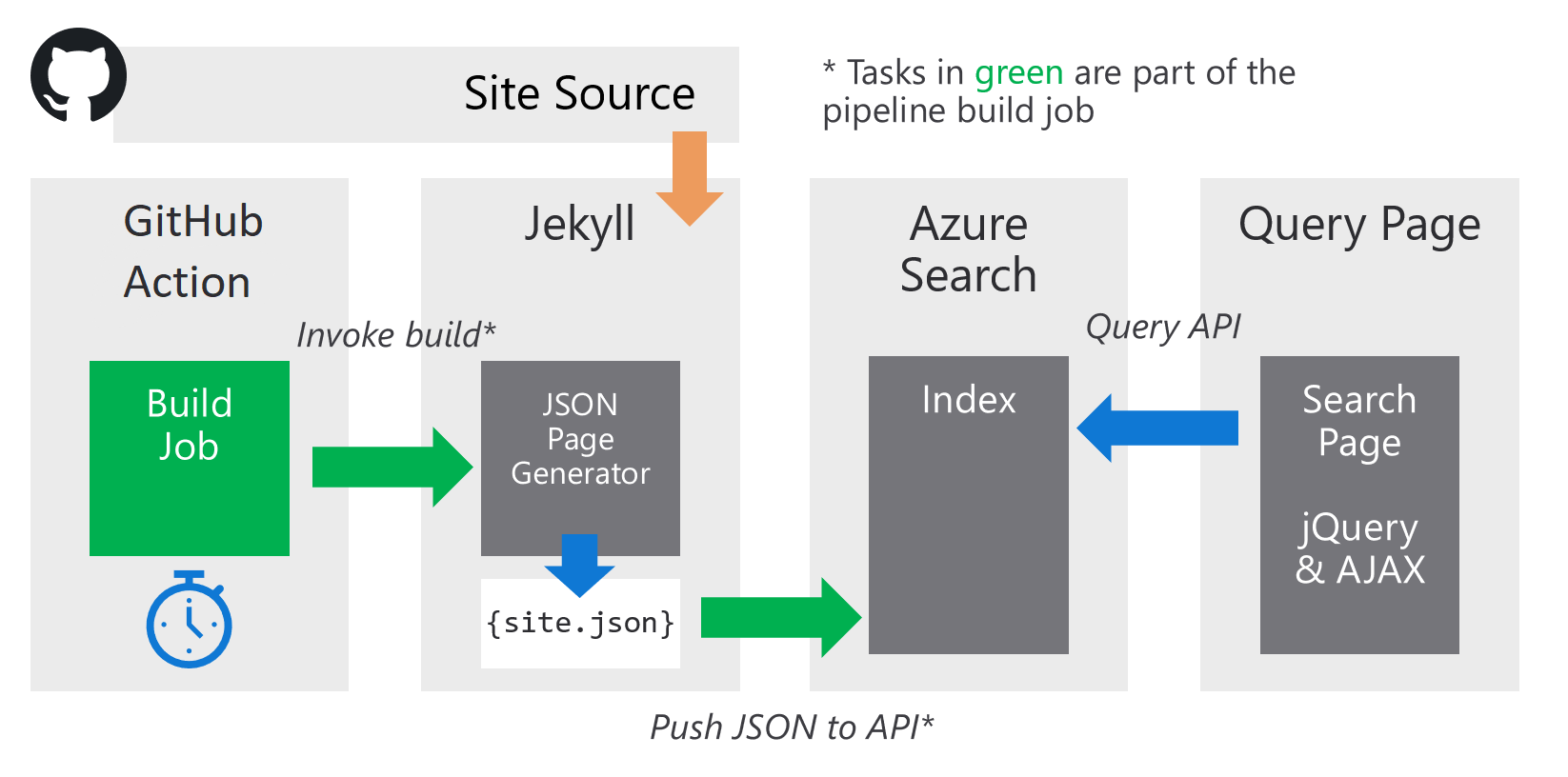
Site JSON Generation
A Liquid template page was created to output the site as a single JSON document, this page resides in _pages/site.json with a permalink set to /site.json so it outputs to the root of the site. It loops over all pages in the site when the Jekyll build is run. The resulting JSON object is an array of documents in a format ready for Azure Search index to consume. See Azure Search documentation on the required format of the data
- Only pages with .md extension are processed, this stops us processing many of the static/special .html pages on the site
- The
idfield is created from the page URL. This will be used as the key field (as it is unique), Base64 encoding ensures the key is “safe” for Azure Search (no strange characters) - The other fields are mostly copied from the page object directly
- The content is placed in a field called
content @search.actionfield is an instruction to Azure Search
The source of _pages/site.json
---
layout: null
permalink: /site.json
---
{% assign content_pages = site.pages | where_exp: "p", "p.path contains '.md'" %}
{
"value": [
{% for page in content_pages %}
{
"@search.action": "mergeOrUpload",
"id": "{{ page.url | base64_encode }}",
"author": "{{ page.author | join: ', ' }}",
"tags": "{{ page.tags | join: ', ' }}",
"title": "{{ page.title }}",
"teaser": "{{ page.header.teaser }}",
"url": "{{ page.url }}",
"excerpt": "{{ page.excerpt }}",
"date": "{{ page.date | date: "%Y-%m-%d" }}",
"content": {{ page.content | jsonify }}
}{% if forloop.last %}{% else %},{% endif %}
{% endfor %}
]
}
Here’s an example of one element (page) in the array:
{
"@search.action": "mergeOrUpload",
"id": "L2F1dG9tYXRpb24vdGVycmFmb3JtL1RlcnJhZm9ybUVudGVycHJpc2Uv",
"author": "Fred Blogs",
"tags": "tag1, tag2",
"title": "Just An Example",
"teaser": "images/teaser/example.png",
"url": "/stuff/example/",
"excerpt": "Short overview of a very boring thing that doesn't exist",
"date": "2018-10-29",
"content": "<< REMOVED TO SAVE SPACE >>"
},
GitHub Actions - Build & Re-index
To keep the index up to date and fresh, some sort of scheduled automation process was required. GitHub Actions was used for this as it has the ability to run the Jekyll build tasks and is flexible enough to automate the other steps required.
The automation is done as a single action in GitHub. The workflow was defined in YAML and is shown in full below
name: Build Search Index
on:
push:
branches:
- master
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
- name: Set up Ruby 2.6
uses: actions/setup-ruby@v1
with:
ruby-version: 2.6.x
- name: Install dependencies
run: |
gem install bundler -N
gem update bundler
- run: bundle install
- name: Build Site
run: bundle exec jekyll build
- name: Push site.json to Azure Search
run: |
curl -v -H "api-key: ${SEARCH_ADMIN_KEY}" -H "Content-Type: application/json" --data-binary "@_site/site.json" -X POST "https://${SEARCH_ACCOUNT}.search.windows.net/indexes/${SEARCH_INDEX}/docs/index?api-version=2017-11-11"
env:
SEARCH_ACCOUNT: $
SEARCH_ADMIN_KEY: $
SEARCH_INDEX: $
A summary of pipeline:
- Environmental setup (Ruby and bundler)
- Run
bundle exec jekyll buildto build the site, to default output directory_site - Using curl, call the Azure Search REST API and push the JSON results (site.json) as a single POST
Secrets and other variables are held in the settings of the repository on GitHub. These are imported into environment variables when the action is run to avoid secrets or other variable settings needing to be hardcoded into the workflow.
The workflow runs on any push to master in the Git repo that contains the site
Azure Search Configuration
Azure Search is a powerful search as a service capability available as PaaS within Azure. For this integration the set up was fairly simple, an Azure Search instance (i.e. account) was created on the Free tier using the Azure Portal. This was a one time task so was not automated.
As the Azure Portal experience for managing and fully configuring Azure Search is quite limited, the REST API was used to setup and configure the service. Postman was used to provide a nice interface to work with the API.
To assist using the API with Postman, the following can be used:
To use simply download & import into Postman, then configure the variables in ‘Azure Search’ environment to match your setup.
As the documents to be indexed are pushed directly to the API, certain featured of Azure Search such as data source and indexer are not required. The only aspect that needs to be setup & configured is an index
Azure Search - Index
The Azure Search index determines which fields will be searchable and returned when querying, and holds the actual data (at least in index form)
Notes on index fields:
- Custom
idfield used as a key, created by thesite.jsongeneration template page - Main searchable fields are
content,title,tagsandexcerpt - Other fields marked as retrievable are:
url,date,authorandteaser - All fields are strings
Example index JSON:
{
"name": "citadel-index",
"fields": [
{
"name": "id",
"key": true,
"retrievable": true,
"type": "Edm.String"
},
{
"name": "content",
"retrievable": false,
"searchable": true,
"type": "Edm.String"
},
{
"name": "title",
"retrievable": true,
"searchable": true,
"type": "Edm.String"
},
{
"name": "tags",
"retrievable": true,
"searchable": true,
"type": "Edm.String"
},
{
"name": "excerpt",
"retrievable": true,
"searchable": true,
"type": "Edm.String"
},
{
"name": "url",
"retrievable": true,
"searchable": false,
"type": "Edm.String"
},
{
"name": "author",
"retrievable": true,
"searchable": false,
"type": "Edm.String"
},
{
"name": "date",
"retrievable": true,
"searchable": false,
"type": "Edm.String"
},
{
"name": "teaser",
"retrievable": true,
"searchable": false,
"type": "Edm.String"
}
]
}
Search Page
To consume or use the search index and actually find results, a client page was created using jQuery. As the site in question is static HTML more modern JavaScript frameworks were deemed to complex to integrate with the site. The search experience is a single query field, and results are fetched & shown in real time as they are typed
The page is very simple, mostly self contained & consists of:
- Search input field bound with keyup events (using jQuery)
- Area for results to dynamically be displayed
- Function to call Azure Search query API (using jQuery AJAX), parse results & update the page
- Delay callback function
- Simple spinner to give user feedback on activity
The basic form is the Azure Search query API is used as follows
GET https://${AZURE_SEARCH_ACCOUNT}.search.windows.net/indexes/${AZURE_SEARCH_INDEX}/docs?api-version=2017-11-11&api-key=${AZURE_SEARCH_KEY}&search={QUERY}
The delay function prevents us overloading the API with requests, so API calls are only made after the user has stopped typing for 500 milliseconds. The API call is made with jQuery, however something like Fetch could have been used.
The API results are parsed as JSON, and certain fields such as header run through JSON.parse() as they contain embedded JSON strings for nested objects. The url can be used to form a link to the relevant page, and fields such as header.teaser, title, excerpt, date & author allow for display of meaningful results on the page. The parsed results are pushed back to the page with a dynamic element and jQuery append.
There’s one other task the search page performs, and that’s to track search events in Azure Application Insights for analytics & reporting. For Azure Citadel, App Insights had already been setup and all pages instrumented with the standard JavaScript code snippet. The search page sends two types of custom event to App Insights using appInsights.trackEvent, one called “Search” for a completed search (where results > 0) and another called “Click”. The two events can be correlated together with the id parameters provided in the events
This is fully documented in the Azure Search Docs:
Search Traffic Analytics ⇒
The source of the page created can be found in the Citadel GitHub repo
For a working demonstration simply click the search link on this site’s toolbar!
Leave a comment